I am merging this blog with andrescaicedo.wordpress.com, where all teaching-related entries will be posted from now on.
305 – Projects
May 9, 2012As mentioned before, I asked my 305 students to write a short paper as a final project. I am posting them here, with their permission; it is my hope that people will find them useful. There are some very nice papers here.
- The 17 plane symmetry groups. By Samantha Burns, Courtney Fletcher, and Aubray Zell.
- The Banach-Tarski paradox. By Josh Giudicelli, Chantel Kelly, and James Kunz.
- The quaternions & octonions. By Kyle McAllister.
- The pocket cube. By Mike Mesenbrink, and Nicole Stevenson.
- 17 plane symmetry groups. By Anna Nelson, Holly Newman, and Molly Shipley.
- The Banach-Tarski paradox and amenability. By Kameryn Williams.
 Leave a Comment » |
Leave a Comment » |  305: Abstract Algebra I |
305: Abstract Algebra I |  Permalink
Permalink
 Posted by andrescaicedo
Posted by andrescaicedo
515 – Caratheodory’s characterization of measurability (Homework 3)
April 12, 2012This set is due Friday, April 27.
The goal of these problems is to prove Carathéodory‘s theorem that “extracts” a measure from any outer measure. In particular, when applied to Lebesgue outer measure, this construction recovers Lebesgue measure.
Leave a Comment » | 515: Analysis II | Permalink
Posted by andrescaicedo
305 – A brief update on n(3)
April 12, 2012This continues the previous post on A lower bound for 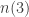
Only recently I was made aware of a note dated November 22, 2001, posted on Harvey Friedman‘s page, “Lecture notes on enormous integers”. In section 8, Friedman recalls the definition of the function 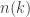
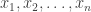
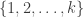
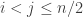
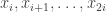
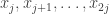
Friedman says that “A good upper bound for
Theorem.
, where
.
Here, 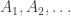
He also indicates a much larger lower bound for 

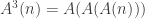
Theorem. Let
. Then
.
He also states a result relating the rate of growth of the function 
There is a recent question on MathOverflow on this general topic.
Leave a Comment » | 305: Abstract Algebra I | Tagged: Harvey Friedman, Pavel Pudlak, Petr Hajek | Permalink
Posted by andrescaicedo
305 – Derived subgroups of symmetric groups
April 11, 2012One of the problems in the last homework set is to study the derived group of the symmetric group 
Recall that if 
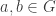
![{}[a,b]=aba^{-1}b^{-1}](https://s0.wp.com/latex.php?latex=%7B%7D%5Ba%2Cb%5D%3Daba%5E%7B-1%7Db%5E%7B-1%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The derived group 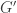
Note that, since any permutation has the same parity as its inverse, any commutator in 
The following short program is Sage allows us to verify that, for 
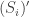




Leave a Comment » | 305: Abstract Algebra I | Permalink
Posted by andrescaicedo
305 – Cube moves
April 11, 2012Here is a small catalogue of moves of the Rubik’s cube. Appropriately combining them and their natural analogues under rotations or reflections, allow us to solve Rubik’s cube starting from any (legal) position. I show the effect the moves have when applied to the solved cube.
But, first, some relevant links:
- Rubik’s Cube World Records. Here is the video to the current record.
- Lego Rubik’s Cube Solver. And the current mechanical record, the CubeStormer II.
- Thomas Rokicki, “Twenty-two moves suffice for Rubik’s Cube®“. Math. Intelligencer, vol 32 (1), (2010), 33–40.
- Exactly 20 moves are required: “God’s number is 20“. Moves are counted here in the Half-turn metric, where any turn on any face by any angle is one move.
Leave a Comment » | 305: Abstract Algebra I | Permalink
Posted by andrescaicedo
305 – Homework V
April 9, 2012This is the last homework set of the term. It is due Friday, April 27, 2012, at the beginning of lecture, but I am fine collecting it during dead week, if that works better.
2 Comments | 305: Abstract Algebra I | Permalink
Posted by andrescaicedo
305 – Homework IV
March 7, 2012This homework set is due Wednesday, March 21, at the beginning of lecture.
Leave a Comment » | 305: Abstract Algebra I | Permalink
Posted by andrescaicedo
197 – Introduction to mathematical thought. Announcement and syllabus
March 5, 2012This Fall I will be teaching a course in the Honors College, Math 197: Introduction to mathematical thought.
The goal of the course is to present an introduction to the mathematical method, the way mathematics is reasoned, discovered, and advanced. This will be accomplished through a presentation of selected (real world) examples, and an emphasis on the key notion of mathematical proof. Particular attention is paid to aesthetic, historical, and philosophical aspects of mathematics.
Pre-requisites: Instructor’s approval.
Text: We will use several texts and articles. Particularly recommended are:
- T.W. Körner. The pleasures of counting, Cambridge University Press (1996). ISBN: 0-521-56087-X (hardback), 0-521-56823-4 (paperback).
(This will be our official textbook, but we will draw material from all three.)
- Sh. Stein. How the other half thinks. Adventures in mathematical reasoning, McGraw-Hill (2001). ISBN-10: 0071407987, ISBN-13: 978-0071407984.
- W. Dunham. Journey through genius. The great theorems of mathematics, John Wiley & Sons, Inc (1991). ISBN-10: 014014739X, ISBN-13: 978-0140147391.
I will provide additional handouts and references as needed. Supplementary recommendations include:
- I. Lakatos. Proofs and refutations. The logic of mathematical discovery, Cambridge University Press (1976). ISBN-10: 052121078X, ISBN-13: 978-0521210782.
- Ph.J. Davies and R. Hersh. The mathematical experience, Mariner Books (1999). ISBN-10: 0395929687, ISBN-13: 978-0395929681.
- S.G. Krantz. The proof is in the pudding. The changing nature of mathematical proof, Springer (2011). ISBN-10: 0387489088, ISBN-13: 978-0387489087.
Contents: We will present a series of examples illustrating how mathematics is used in the real world, and how it is conceived. We will discuss the nature of mathematical proof, and some of the philosophical issues surrounding it, as well as how it has evolved through the ages. The goal is to see how mathematicians actually reason, and how mathematical ideas are a natural part of the cultural legacy of humankind.
Specific examples may be chosen depending on the audience background and motivation. Particular examples I would like to include are the mathematics of
codes, how populations evolve through time, the mathematics of infinity, and computer generated proofs.
Grading: Grades will be determined based on homework (60%), a written project (20%), and class participation (20%). There will be no exams.
Attendance to lecture is not required but highly recommended.
I will use this website to post additional information, and encourage you to use the comments feature. If you leave a comment, please use your full name, which will simplify my life filtering spam out.
Leave a Comment » | 197: Introduction to mathematical thought | Permalink
Posted by andrescaicedo
580 – Topics in Set Theory. ANNOUNCEMENT
March 5, 2012This Fall I will be teaching Topics in set theory. The unofficial name of the course is Combinatorial Set Theory.
We will cover diverse topics in combinatorial set theory, depending on time and the interests of the audience, with emphasis on three topics: Choice-free combinatorics, cardinal arithmetic, and partition calculus (a generalization of Ramsey theory).
Time permitting, we can also cover large cardinals, determinacy and infinite games, or cardinal invariants (the study of sizes of sets of reals), among others. I’m open to suggestions for topics, so feel free to email me or to post a comment.
Pre-requisites: Permission by instructor. The recommended background is knowledge of cardinals and ordinals. A basic course on set theory (like 502: Logic and Set Theory) would be ideal but is not required.
Grading: Based on homework.
Textbook: Combinatorial set theory, by Neil H. Williams. Elsevier Science (1977). ISBN-10: 0720407222, ISBN-13: 978-0720407228. The book seems to be out of print.
We will also use:
- Combinatorial Set Theory: Partition Relations for Cardinals, by Paul Erdös, András Hajnal, Attila Máté, and Richard Rado. Elsevier Science (1984). ISBN-10: 0444861572, ISBN-13: 978-0444861573. Apparently, this is also out of print.
I will distribute notes on the material of these books, on additional topics, and some papers that we will follow, particularly:
- András Hajnal and Jean A. Larson. “Partition relations”, in Handbook of set theory, 129–213, Springer, 2010.
- Jean A. Larson. “Infinite combinatorics”, in Handbook of the history of science, vol. 6, 145-357, Elsevier, 2012.
Leave a Comment » | 580: Topics in set theory | Permalink
Posted by andrescaicedo
